Hastache 0.6.0. Новый мейнтейнер
Вышла новая версия hastache 0.6.0. Самое заметное изменение — переход от использования ByteString к использованию Text.
А самое заметное изменение для меня самого в том, что теперь у hastache новый мейнтейнер, который вот эту новую версию и выпустил. Это Daniil Frumin. Я отошел от разработки hastache просто по причине отсутствия у меня активных проектов с его использованием, а людям надо, кто-то пользуется, вот Daniil и попросился на эту роль. Теперь у меня такое странное чувство по этому поводу. С одной стороны приятно, что там что-то такое написал, а вот теперь оно совсем своей жизнью зажило. С другой стороны, эх времени бы мне немного свободного, сесть и переписать все совсем по другому, по правильному, API можно еще немного обобщить, парсер переписать...
Большие данные

Недавно ко мне обратилась представительница издательства «Манн, Иванов и Фербер» с предложением прочитать и написать отзыв об одной из их новых книг. Тема предложенной книги мне была не интересна и в ответ на мой отказ, она предложила выбрать для обзора любую из изданных этим издательством книг. Я выбрал книгу «Большие данные». Тут надо сделать небольшое отступление: из русскоязычных издательств «МИФ» мне нравиться, пожалуй, больше всех, так что сильно упрашивать меня не пришлось. (Бросить все это программирование? Стать известным литературным критиком?)
Следует сразу сделать небольшое замечание касаемо самого этого термина «большие данные». Лично для меня это было новостью. Авторы книги пишут что под словом «большие» следует понимать не столько объем данных, сколько полноту выборки («N = все»). В докомпьютерную эпоху для анализа каких-то данных необходимо было для начала выполнить из них случайную выборку такого объема, который еще поддается ручному анализу. На основе анализа этого небольшого объема делалось предположение о всех данных целиком (это и сейчас актуально, например, для социологических исследований, только тут сложность в самом сборе данных). Когда мы входим в мир больших данных, то уже нет необходимости делать предварительный отбор из всего их объема, мы анализируем все целиком. В книге приводиться пример выявления договорных боев в японской борьбе сумо с помощью статистического анализа. Весь входной объем данных, это всего чуть больше 64000 поединков — совершенно смешной объем для того что мы привыкли подразумевать под термином «большие данные». Однако, с точки зрения авторов книги, это большие данные и есть, ведь для анализа были использованы результаты всех боев (N = все) за много лет.
Нет смысла пересказывать области применения больших данных, которые упомянуты в книге — лучше ее просто прочитать. Там много примеров. А для интересующихся темой сейчас вообще время хорошее: большие данные в моде, в новостях постоянно описывают все новые их применения.
Эпоха больших данных — это не что-то такое, к чему надо готовиться, это уже наша объективная реальность, ставшая возможной благодаря повсеместной датификации (перевода информации в пригодный для анализа цифровой вид). И как у любой мощной технологии у нее есть две стороны.
С одной стороны, большие данные буквально спасают жизни. Например непрерывный мониторинг медицинских показаний недоношенных младенцев, с учетом ранее проанализированных замеров, позволяет распознать начало развития инфекции, когда никаких внешних признаков еще нет. В данных инфекция уже заметна, и лечение можно начать сразу.
С другой стороны, большие данные бросают вызов сохранению конфиденциальности и приватности. Анализируя потребления электроэнергии человеком можно многое узнать о его привычках. Или сравнивая поведение людей на сайтах скрывающих реальные имена и сайтах где реальные имена известны, можно с достаточно высокой точностью идентифицировать конкретного человека (в книге есть пример раскрытия реальных имен пользователей на основе анонимизированных данных с сервиса проката фильмов Netflix при сравнении их с реальными именами пользователей сайта IMDb).
Также есть риск захода совсем уже на темную сторону. Скажем может появиться искушение прогнозирования будущего поведения человека, для пресечения возможных правонарушений, до их непосредственного совершения. Просто потому, что анализ данных показал высокую вероятность таких событий. Антиутопия в чистом виде — человек еще ничего не сделал, но проблемы у него уже есть.
Важно понимать, большие данные показывают нам что-то на основе того что уже было. Предсказать нечто принципиально новое они не в состоянии. Так что мир человеческого интеллекта, творчества, прозрений, изобретательности остаются, к счастью, за нами, несмотря на весь прогресс в гигагерцах, терабайтах и алгоритмах.
Про удаленную работу

Прочитал книжку REMOTE от 37signals. Книжка посвящена вопросам организации удаленной работы. Написана на их собственном опыте существования в условиях когда большая часть штата компании географически находится далеко друг от друга. Книжку рекомендую, мне очень понравилась.
В этом декабре исполнилось 6 лет как я сам работаю из дома, и чем дальше тем больше мне это нравится. Опыта руководства географически распределенных команд у меня нет, но опыт работы в таких командах есть, и вот в честь юбилея моей домашней работы (10 в шестиричной системе счисления, в следующем году будет 10 в семиричной, очень удобно) я бы хотел поделится своим опытом.
Про стояние с кнутом
По моему опыту, большинство потенциальных менеджеров задумывающихся об организации удаленной работы, больше всего переживают что без стоящего над душой начальника с кнутом работа вообще сделана не будет. Господа, ну это полная ерунда, как будто в офисе мало возможности ничего не делать. Даже попытки закрывать доступ к разным там одноклассникам и вконтактам приводит просто к росту доступа к ним с мобильных. Сейчас, я так понимаю, доля таких пользователей соцсетей измеряется десятками процентов. И там очень много вот как раз таких, работающих в компаниях с ограниченным интернетом. Додумались ли где-то уже отбирать сотовые в начале рабочего дня я не знаю. Но рабов к галере лучше всего сразу цепью приковывать.
Выполнение современной работы, особенно в IT, особенно у программистов, совершенно тривиально отслеживается просто по факту выполнения нужной работы. За эти 6 лет ни разу никого не заинтересовало в какое время я работаю или сколько часов провожу за монитором или как часто захожу в соцсети. Вопрос был только один — как движется работа.
Про самомотивацию
Обратная сторона предыдущей медали. «Если меня не пинать постоянно, я и делать ничего не буду», — распространенная мысль многих наемных работников. Это, на самом деле, довольно серьезная проблема. Разбирайтесь зачем вам нужна работа и какая она должна быть, может удастся найти хоть какую-то положительную мотивацию чтоб ее выполнять, или сменить работу на ту что больше по душе. С мотивацией основанной на страхе жить не очень приятно. Как краевед говорю.
Про настоящие трудности
Единственная большая проблема с которой лично я столкнулся за эти годы — это дефицит общения. Если из дома выходишь только в магазин, да еще и домашние куда-нибудь разъехались, начинаешь натурально дичать. В офисе хоть коллеги есть, и по пути на работу и с работу какое-никакое общение, живых людей видишь. А тут надо серьезно думать что делать. Помогают разные там хобби, я, например, дважды в неделю собираю небольшую группу занимающихся цигун у себя дома, вместе занимаемся, потом чай пьем. И польза от цигуна и польза от общения.
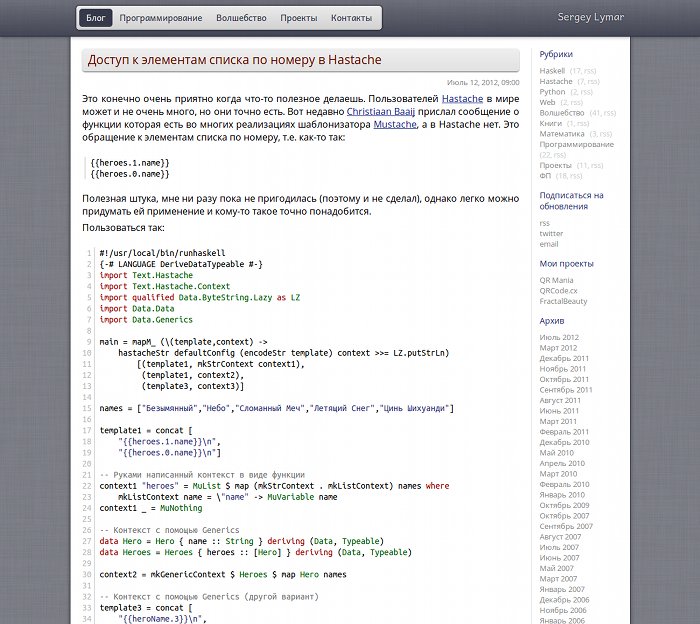
Про физическую нагрузку
Это тоже проблема. Когда расстояние кровать-кухня-компьютер в сумме метров 20, физическая форма сами понимаете какая становится. 37signals пишут, что они даже компенсируют расходу на фитнес клубы для своих работников — замечательная идея.
Тут мне, надо сказать, нечем похвастаться, я что-то делаю в смысле спорта, но этого явно мне недостаточно. Продолжаю работать над этим вопросом.
Про организацию рабочего места
Тут мне натурально повезло, у меня есть возможность дома одну комнату занять под кабинет где я и работаю. В REMOTE перечисляются разные варианты где можно еще работать: кафе, коворкинг центры и т.п. Я пока не пробовал, мне дома нормально.
С интернетом сейчас тоже все замечательно. Периодически я в деревню уезжаю, там нет воды в кране (как и самого крана), нет канализации, дорог тоже можно сказать что нет, но быстрый интернет в телефоне там есть, такой вот изгиб технического прогресса.
Про плюсы
Много времени высвобождается. Никакого переполненного общественного транспорта (или стояния в пробках), где и теряются эти 1-2-3-… часа в день у офисных работников.
Рабочее место организована как угодно по собственному вкусу. Хороший монитор, клавиатура, кресло.
Рабочее время выбирается по вкусу. Можно хоть в 6 утра начать работать и к обеду все переделать, можно рано утром часть работы, потом еще немного вечером. В середине дня можно в магазин сходить, а не толкаться там в 19 часов когда туда все после офисного рабочего дня приходят.
С семьей больше времени проводишь. Папа конечно днем занят и работает, но иногда отвлечь можно.
Питаться можно вкусной домашней только что приготовленной едой, а не в непонятных кафешках и столовых.
Про хорошо
Я, как и авторы книжки REMOTE, считаю что чем дальше тем больше людей будет удаленно работать. Плюсов много, минусов мало.
Если вы работодатель, прочитайте REMOTE и подумайте об организации удаленной работы у себя.
Если вы работник, прочитайте REMOTE и агитируйте своего работодателя начать организацию удаленной работы. Можно вот как раз с вас.
UPD: В издательстве «Манн, Иванов и Фербер» вышел русский перевод книги.
Резервное копирование с BitTorrent Sync
Что за зверь?
BitTorrent Sync — совершенно замечательный сервис, запущенный авторами всеми нами любимого протокола BitTorrent в апреле 2013. Это сервис синхронизации файлов, при этом синхронизация по возможности происходит напрямую между устройствами, без использования центрального сервера для передачи (т. е. по технологии peer-to-peer). P2P природа дает одно серьезное преимущество перед сервисами облачного хранения файлов (Dropbox, Яндекс.Диск, Google Drive) которые многие используют для синхронизации своих устройств: в P2P мы никак не ограничены объемами синхронизируемых данных, нужно передать терабайт данных, на здоровье, хватило бы пропускной способности сети и объема дисков на синхронизируемых машинах. В облачных сервисах всегда есть какое-то не очень большое ограничение объема, и за его увеличение нужно доплачивать. Минусом же P2P синхронизации можно назвать необходимость одновременного присутствия в сети синхронизируемых устройств.
Увидев анонс BitTorrent Sync я сразу его попробовал в деле и остался очень доволен: поддерживает все нужные мне платформы, синхронизирует быстро. Я даже удалил за дальнейшей ненадобностью свой аккаунт в DropBox.
Использование для резервного копирования.
Создание резервных копий Важных Данных это всегда интересно. Для себя я с помощью BTSync соорудил такую штуку: завел сервер на Amazon Web Services и поставил на него BTSync. Данные хранятся в Elastic Block Store. Этот самый EBS имеет функцию создания инкрементальных снимков файловой системы. «Инкрементальные» значит что сохраняются только изменения, а не все данные целиком, т. е. если от предыдущего снимка теперешний отличается только добавлением пары мегабайт то и занимать этот новый снимок будет тоже только эти два мегабайта, независимо от объема всего хранилища.
И теперь по крону раз в час на этом удаленном сервере у меня запускается создание нового снимка EBS. Сейчас я храню снимки с часовым разрешением за трое суток, и суточные в течении 15 дней, для меня это совершенно достаточно, даже с избытком честно говоря.
В качестве бонуса у меня есть копия данных не привязанная к моим устройствам, эдакий аналог облачного хранилища по сильно более низким ценам чем у облачных провайдеров.
Ничего из написанного и настроенного выкладывать не буду, пока по крайней мере, там все такое, мммм... надежно склеенное изолентой и на забитых молотком шурупах, нельзя такое людям показывать. Однако если кто желает повторить для себя такую конструкцию и упрется в какую-то непонятность, милости прошу в комментарии.
Математические формулы ТеX в SVG
Оказывается вовсе не обязательно вставлять  -овскую математику в вебе также как это делалось в 1999 году — в виде гифов с прозрачным фоном. Будущее уже давно наступило, теперь можно использовать векторный SVG.
-овскую математику в вебе также как это делалось в 1999 году — в виде гифов с прозрачным фоном. Будущее уже давно наступило, теперь можно использовать векторный SVG.
Это я вот к чему. Недавно, обзаведясь Макбуком с Retina-дисплеем проблема растровой графики в вебе у меня всплыла в полный рост: если раньше, когда часть какой-нибудь странички была отрисована, скажем, фотошопом, а часть средствами CSS, то просто глаз слегка спотыкался на этой разнице, но терпимо было. А на ретине разница становится уже жуткой — растровые части сайтов выглядят как набор больших пикселей.
И если на других сайтах это проблемы их создателей, то на моем собственном блоге (да, да, пишу я в него реже чем ковыряю его движок и дизайн) меня такая разница не устраивала совершенно, и больше всего у меня она видна как раз на вставленных математических формулах.
Полез разбираться как бы математику в SVG рендерить, оказалось что человечество эту проблему давно решило, и есть утилитка dvisvgm ровно для этого и предназначенная. Я вызываю ее так:
| |
Все, на выходе some.svg замечательно выглядящий на ретине.
Наглядная разница между растром и вектором для математики (привет всем владельцам ретина-дисплеев). Растр:
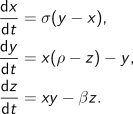
Вектор:

Кстати, чтоб два раза не вставать, сэкономлю кому-нибудь пару часов на разбирательство. У всей математики у меня в блоге вот такой шаблон:
| |
Конвертация репозитория Bazaar в Git
Может кому-то понадобится. Конвертируем репозиторий Bazaar в Git:
1. Делаем резервную копию исходного репозитория.
2. Устанавливаем bzr-fastimport:
| |
3. Конвертируем:
| |
Аттрактор Лоренца
Развлекаюсь с анимацией на HTML5 canvas. Написал вот такую чудесную визуализацию аттрактора Лоренца:
При открывании в новом окне, не забудьте что браузер можно перевести в полноэкранный режим, нажав F11. Так смотрится ещё лучше.
То что вы тут видите, представляет собой анимацию решения системы следующих дифференциальных уравнений:

Где  ,
,  ,
,  — текущее состояние системы,
— текущее состояние системы,  — время,
— время,  ,
,  ,
,  — параметры системы.
— параметры системы.
В моём примере:

Для каждой линии (представляющей собой отдельное решения уравнения) я выбираю начальное значение с добавлением небольшого случайного числа. Таким образом очень хорошо заметен «эффект бабочки»: незначительное возмущение системы («взмах крыла бабочки») приводят к очень большим изменениям в дальнейшем, линии «вылетающие» из очень близких точек вскоре начинают демонстрировать совершенно разное поведение.
Новый движок моего блога
В очередной раз переделал движок своего блога. Теперь у меня чисто статический блог, лежащий в Amazon S3. Предыдущая версия благополучно и без единого нарекания отработала свои год и 9 месяцев. Теперь настало время перемен.
Мне кажется, что суммарное время, которое я трачу на программирование движков своего блога, уже превышает время на то чтобы что-то сюда писать. И уж во всяком случае это явно сравнимые величины.
Окончательным толчком к переходу на чисто статический блог послужило недавнее появление у Amazon S3 функции редиректов, без редиректов всё-таки сложно обойтись. Также, для такого простого сайта как личный блог, держать целый сервер, базу данных, как-то всё это администрировать — явное переусложнение. В последнее время я больше склоняюсь к простым решениям.
Для интересующихся некоторые технические подробности:
Генератор
Тут для меня без вариантов — Haskell. Самый главный действующий персонаж тоже понятен — Hastache, не зря же я его писал.
Организация
Технически каждая запись в блоге выглядит так: отдельная директория с именем типа «2011-02-28 16:03 new engine», внутри лежит файл def.json с заголовком и тегами этой записи, файл text.html с текстом, и какие-нибудь дополнительные файлы (если они в этой записи нужны). Такие вот ракетные технологии блогостроения. Text.html — это не просто чистый html, это ещё и кое-какая дополнительная разметка, например для вставки математических формул ( рулит) или исходного кода с подсветкой синтаксиса (highlighting-kate). Дополнительная разметка большей частью представлена секциями Hastache.
рулит) или исходного кода с подсветкой синтаксиса (highlighting-kate). Дополнительная разметка большей частью представлена секциями Hastache.
Типографика
Ммм, это прямо моя прелесть. Не понимаю чего никто переносов в вебе не делает, намного ведь приятней выглядит, особенно если текст растянут по ширине. Технически сами переносы уже сто лет как доступны во всех браузерах. У меня теперь всё с переносами, красота да и только. Переносы расставляет самописанная библиотека (работает по алгоритму Ляна-Кнута), я её написал для qrmania.ru, и вот опять пригодилась. Надо бы выложить в Hackage, но пока QA-отдел в моей голове этого не позволяет.
Работа с S3
Сначала думал обойдусь s3cmd, но в итоге написал собственный синхронизатор для S3, благо для Haskell есть библиотека aws. Кстати, я в неё закоммитил работу с редиректами S3, но эта версия в настоящий момент ещё не выложена в Hackage, кому срочно надо берите прямо с GitHub.